



Каспийская техническая конференция SPE
Искусственный интеллект в нефтяной промышленности: текущее состояние и будущее
На вопросы Армана Мухамедьярова отвечает доктор Шахаб Д. Мохагех, пионер в области применения искусственного интеллекта и машинного обучения в сфере разведки и добычи

Шахаб Д. Мохагех, пионер в области применения искусственного интеллекта и машинного обучения в сфере разведки и добычи. Он является профессором нефтегазовой инженерии Университета Западной Вирджинии, руководителем компании Intelligent Solutions, Inc. (ISI). Он также является директором WVU-LEADS – лаборатории, занимающейся техническим применением анализа данных.
Доктор Мохагех имеет более 30 лет опыта в исследованиях и разработках в области применения искусственного интеллекта и машинного обучения в нефтяной инженерии.
Он автор четырех книг (“Аналитика в разработке сланцевых нефтей», «Моделирование месторождений на основе данных», «Применение аналитики на основе данных для геологического хранилища CO2», «Моделирование умного прокси»). Он написал более 230 технических документов и выполнил более 60 проектов для независимых, национальных и международных нефтяных компаний.
Является заслуженным лектором Общества инженеров-нефтяников (SPE) (2007 и 2020 гг.), четырежды был удостоен звания заслуженный автор редакционной коллегии журнала SPE Journal of Petroleum Technology (JPT 2000 и 2005 гг.). Др. Мохагех является основателем Технической секции SPE, посвященной искусственному интеллекту и машинному обучению (Petroleum Data-Driven Analytics, 2011). Он был отмечен министром энергетики США за оказанную техническую экспертизу, с применением ИИ при расследовании последствий аварии на платформе Deepwater Horizon (Macondo) в Мексиканском заливе (2011 г.). Также являлся членом технического консультативного комитета министерства энергетики США по нетрадиционным месторождениям при двух президентских администрациях (2008-2014 гг.). Он представлял Соединенные Штаты в техническом комитете Международной организации по стандартизации (ISO) по улавливанию и хранению углерода (CCUS) (2014-2016 годы).
– Др. Мохагех, что такое Искусственный интеллект? Из чего он состоит?

– Сначала давайте разберем определения двух слов: «искусственный» и «интеллект». Затем объединение этих определений даст некоторое понимание о том, что такое «искусственный интеллект» и почему он используется в качестве терминологии для определения этой новой технологии. Слово «искусственный» – это копия чего-то, что является «природным». «Искусственный» создается или производится человеком, а не встречается в природе. Слово «интеллект» означает способность приобретать и применять знания и навыки. «Интеллект» – это способность к логике, пониманию, самосознанию, обучению, эмоциональным знаниям, рассуждениям, планированию, творчеству, критическому мышлению и решению проблем. Прежде чем появился термин «искусственный интеллект», слово «интеллект» относилось к естественному «интеллекту» и человеческому «интеллекту».
Таким образом, термин «Искусственный интеллект» не должен изменять определение «Естественного интеллекта» и «Человеческого интеллекта», скорее он должен означать, что человек создает и производит то, что известно, как «Естественный интеллект» и «Человеческий интеллект». Другими словами, «Искусственный интеллект» – это симуляция «Естественного интеллекта»
Таким образом, определение «Искусственный интеллект» будет симуляцией естественного человеческого «Интеллекта» путем симуляции человеческого мозга с использованием машин (компьютеров).
«Искусственный интеллект» – это симуляция человеческого интеллекта, имитирующая «человеческий мозг» для анализа, моделирования и принятия решений.
– Очень часто «машинное обучение» упоминается в связке с термином «Искусственный интеллект». Точно так же мы часто слышим такие термины, как «глубокое обучение», «обучение с подкреплением» и «контролируемое обучение». Не могли бы вы структурировать все эти (и любые другие релевантные) термины в контексте Искусственного интеллекта для лучшего понимания?
– Машинное обучение – это серия алгоритмов, которые используются для создания «искусственного интеллекта». До создания и использования «Искусственного интеллекта» никакие подходы, основанные на данных, не назывались «машинным обучением». Поскольку определенные виды «Интеллекта», такие как наука и инженерия, требуют «Обучения», а «Машина» является инструментом для «Искусственного» развития «Интеллекта», развитие «Искусственного интеллекта» предполагает использование «Машинного обучения». Опять же, сначала давайте определим значения двух слов «машина» и «обучение». После этого объединение этих определений даст некоторое понимание о том, что такое «машинное обучение», и почему оно используется в качестве терминологии для определения этой новой технологии.
Слово «машина» в контексте выполнения алгоритмов относится к «компьютерам».
Слово «обучение» означает процесс приобретения нового понимания, знаний, поведения, навыков, ценностей, отношений и предпочтений. Поскольку алгоритмы «машинного обучения» используются для разработки и создания «искусственного интеллекта», то определение «искусственного интеллекта», упомянутое в предыдущем разделе, предполагает, что «машинное обучение» будет следовать тому пути, по которому естественный человеческий «интеллект» проходит в процессе обучения. Другими словами, машины должны обучаться так же, как и люди. Однако, учитывая тот факт, что машины (компьютеры) – это не то же самое, что люди, при этом «Обучение» должно соответствовать тем же требованиям (что и для людей), очевидно, что оно не может быть применено аналогично.
Идея состоит в том, чтобы показать, как люди учатся, а затем посмотреть, как могут обучаться компьютеры. В этом конкретном применении «искусственного интеллекта» в науке и технике следует уделить внимание человеческому изучению науки и техники, а затем попытаться выяснить, как машины могут обучиться тому же. В этом контексте давайте сначала определим, как люди изучают науку и технику? Совершенно очевидно, что для того, чтобы люди изучали науку и технику, им необходимо несколько лет обучаться в университете. Когда люди идут в университет, чтобы узнать о науке и технике, с чем они сталкиваются? Совершенно очевидно, что профессора в университете «учат» темы конкретного курса студентам, чтобы они могли «обучиться («освоить»).
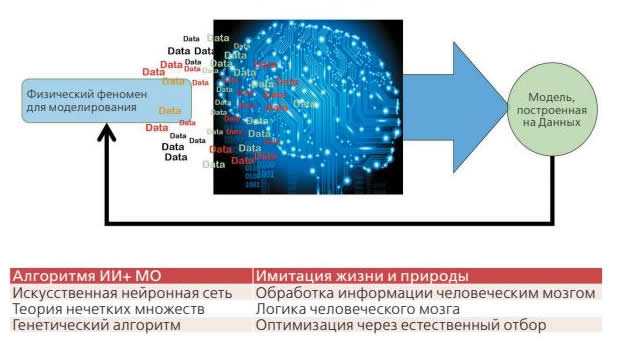
В Общем интеллекте обучение может осуществляться посредством вовлечения и опыта, тем не менее, обучение также может быть полезным, хотя и не обязательно является абсолютным требованием, поскольку «Общий интеллект» является частью мозга человеческого вида. Однако, когда дело доходит до науки и техники, «Изучение» обязательно требует «Обучения». Поскольку это часть «Естественного человеческого интеллекта», то в применении к «Искусственному интеллекту» это должно быть применено посредством «Машинного обучения». Возьмем тот же пример, когда «профессора в университете «учат» студентов, чтобы они могли «обучиться» темам во время посещения какого-либо курса. Каким будет ответ на следующий вопрос: может ли профессор в университете «учить» тему, в которой он/она не является экспертом? Ответ однозначен: «НЕТ»
Чтобы преподавать что-то, вы должны быть экспертом в этой теме и очень хорошо ее знать, чтобы найти лучший способ донести и обучить суть и детали темы студентам, посещающим курс, чтобы они могли «выучить» его. То же самое относится и к «машинному обучению» в научном и инженерном применении «искусственного интеллекта». Экспертиза предметной области является обязательным условием для анализа, моделирования и решения проблем, связанных с наукой и техникой с применением «Искусственного интеллекта» и «Машинного обучения».
Глубокое обучение – это ссылка на использование нескольких скрытых слоев в искусственных нейронных сетях, которые представляют собой алгоритмы машинного обучения, используемые для разработки искусственного интеллекта.
Неконтролируемое обучение означает, что входные данные, которые используются в алгоритмах машинного обучения, не содержат никаких выходных данных или результатов. Идея применения неконтролируемого обучения к предоставленным данным состоит в том, чтобы найти информацию о данных, показывающую, какие их части ближе и похожи друг на друга в нескольких разделах. Это также называется Классификацией.
Контролируемое обучение означает, что входные данные используются для обучения искусственных нейронных сетей, которые являются алгоритмами машинного обучения, при этом выдавая определенные выходные данные в соответствии с заданными исходными данными. В Контролируемом обучении алгоритм машинного обучения стремится прийти к результату, полученному из обработки входных данных, примененных в процессе «обучения».

– Инженер по машинному обучению (ML) и Специалист (Ученый) по данным (Data Scientist). Являются ли эти два названия синонимами друг друга (очень часто они используются таким образом) с точки зрения роли, которую они играют? Разные источники дают разные ответы на этот вопрос.
– За последние пару десятилетий много людей стало интересоваться искусственным интеллектом, и было показано, что он может решать массу задач, которые в прошлом сделать было нельзя. Существуют серьезные различия в том, как искусственный интеллект должен использоваться для тем, связанных с наукой и техникой, и тем, как он используется для областей общего интеллекта.
В общем, то, как сегодня употребляются эти слова, во многом относится к одному и тому же. Тем не менее, с течением времени многие из этих вопросов станут более конкретными, поскольку сегодня любой, кто даже просто просматривает данные, называет себя «Data Scientist».
– На ваш взгляд, где искусственный интеллект применим лучше всего в нефтяной инженерии сектора Upstream? В дисциплинах, которые являются более осязаемыми (то есть механическими) по своей природе, такими как, например, бурение и подземный ремонт скважин; или в подземных дисциплинах, таких как геология, петрофизика, разработка месторождений и т.п., которые характеризуются «неосязаемостью»; или может быть в дисциплине добыче углеводородов, являющейся «пересечением» подземных и наземных дисциплин?
– Основываясь на моем личном опыте работы с задачами нефтяной инженерии, связанными как с подземными, так и с наземными (дисциплинами), при правильном использовании (а не «Гибридные модели») искусственный интеллект может дать отличные результаты. В Petroleum Data Analytics (PDA), которая представляет собой приложение искусственного интеллекта к нефтяной инженерии, идея состоит в том, чтобы избегать каких-либо предположений, интерпретаций и упрощений. Вместо этого PDA помогает решать все задачи, связанные с подземными и поверхностными работами, на основе фактов и реалистичности реальных полевых измерений. Мы разработали такие технологии (включая программные приложения) для симулирования и моделирования разработки коллекторов на основе ИИ, оптимизации добычи из сланцевых скважин, бурения и наземных объектов.

– Исторически, инженеры-нефтяники в своей повседневной работе в значительной степени полагаются на «эмпирический подход» (корреляции, интерпретации). В технологии искусственного интеллекта же, наоборот, используются исключительно «жесткие», т. е. измеренные данные. Что вы думаете о возможности искусственного интеллекта «изменить» практику нефтяной инженерии, создав тем самым «сдвиг парадигмы»?
– Как уже упоминалось в предыдущем ответе, исторический подход к решению проблемы нефтяной инженерии включает в себя предположения, интерпретации и упрощения. На самом деле это верно в отношении традиционного решения инженерных задач, использующего математические уравнения для моделирования физических явлений. В искусственном интеллекте, который представляет собой полный сдвиг парадигмы по сравнению с традиционным решением инженерных задач, идея состоит в том, чтобы избегать предположений, интерпретаций, упрощений и даже предубеждений. Когда для решения проблемы используются только фактические «точные» данные, тогда главным источником решения проблемы будут только факты и реальность, а не «то, что мы думаем» или «что нам нравится».
Однако, когда некоторые инженеры используют «гибридные модели», они делают то же самое, что и до «сдвига парадигмы». т.е, до Искусственного интеллекта. Те, кто занимается «гибридными моделями», скорее всего, сначала пытались использовать только фактические данные, но отсутствие понимания и опыта в области искусственного интеллекта не принесло им успеха. Затем они сгенерировали «мягкие данные», которые генерируются математическими уравнениями (точно так же, как мы традиционно решали задачи, основанные на физике), и объединили их с фактическими данными. Данные, сгенерированные математическими уравнениями, уже включают закономерности и корреляции. По этой причине «гибридные модели» действительно работают, но они не имеют АБСОЛЮТНО НИЧЕГО общего с искусственным интеллектом.
– С распространением искусственного интеллекта в промышленности можно ли ожидать, что значение КИПиА, как отрасли машиностроения, «отвечающей» за предоставление точной информации, поступающей непосредственно от различных датчиков, манометров и других измерительных устройств, будет постоянно расти?
– Дело в том, что все полевые измерения включают в себя некоторые неопределенные и зашумленные данные. Тем не менее, хотелось бы надеяться, что фактические полевые измерения, которые предоставляются инженерам-нефтяникам, не «скомпонованы» определенным образом, и все они были фактически измерены. Учитывая определение искусственного интеллекта, данное в ответ на первый вопрос, искусственный интеллект пытается работать как человеческий мозг.
То же самое, что было упомянуто (неопределенные и некоторые зашумленные данные), верно и в отношении данных, которые человеческий мозг использует постоянно. Все, что мы делаем, основано на фактах и реальности, которые мы видим и слышим все время, тем не менее, даже если факты содержат в себе неопределенность и некоторый шум, мы все равно можем найти правильное решение. Представьте, что кто-то бросает мяч в ребенка. Фактическая начальная скорость броска мяча или фактический угол улавливаются мозгом ребенка не в точных значениях, а в неопределенной и «шумной» для данных форме. Тем не менее, ребенок после нескольких неудачных попыток ловит мяч. То же самое можно сказать и о реальных полевых измерениях, которые мы используем для решения инженерных задач с помощью искусственного интеллекта.
– В настоящий момент, с внедрением ИИ, множество компаний сектора Upstream, давно присутствующие на рынке, и новые, чтобы акцентировать альтернативный способ построения предлагаемых ими моделей, используют такие термины, как «Построенные на данных», «Основанные на физике» и «Построенные на основе физике» модели.
В то время как смысл термина «Модели, построенные на данных» (т.е. построенные на основе данных – полностью или частично) – не требует пояснений, возникает вопрос к термину «Модель, основанная на физике». Обоснование того, что эти модели подчиняются законам физики, приводит к одному логичному вопросу: на чем они основывались ранее, когда ИИ еще не было, если как не «на физике»?
– К сожалению, многие крупные сервисные компании и почти все поставщики используют термин «искусственный интеллект» и «машинное обучение» в качестве инструмента маркетинга, а не научного инструмента. Основная причина этого заключается в том, что у них очень слабое и нереалистичное понимание искусственного интеллекта. Данный вопрос, который вы задали, ясно указывает на проблему, и причина этого в следующем. Когда эти компании используют термин «Модель, построенная на данных», они думают, что данные в ИИ используются так же, как и в традиционной статистике. Скорее всего, у них есть некоторый опыт в традиционной статистике (с прошлого века это широко применяемый концепт в нефтяной инженерии), но для создания впечатления, что они применяют искусственный интеллект при создании таких моделей, используют слово «Построенный на данных». Одна из главных проблем таких компаний заключается в том, что они не осознают, что искусственный интеллект сильно отличается от традиционной статистики, хотя в обоих случаях данные используются для решения проблем. Когда они используют термин «основанный на физике» или «управляемый физикой», это обычно означает, что они добавляют данные, связанные с физикой, для решения проблемы с помощью ИИ. Они используют математические уравнения для генерации данных, связанных с физикой. Большой объем данных генерируется и добавляется к фактическим данным, которые они собрали.
– Продолжая тему моделирования: не могли бы вы выделить основные достижения в области моделирования с изобретением ИИ/МО?
– Дело в том, что искусственный интеллект может моделировать физические явления, используя реально измеренные данные. Следует отметить, что способ, которым искусственный интеллект моделирует физические явления, сильно отличается от традиционного инженерного подхода к моделированию физических явлений. Традиционно, как инженеры, мы сначала определяем параметры и переменные, которые являются частью данного физического явления, а затем используем математические уравнения для взаимодействия параметров и переменных друг с другом, чтобы наилучшим образом смоделировать физическое явление. Затем мы запрашиваем и ищем данные, которые представляют параметры и переменные, чтобы они могли соответствовать нашему математическому уравнению модели физического явления.
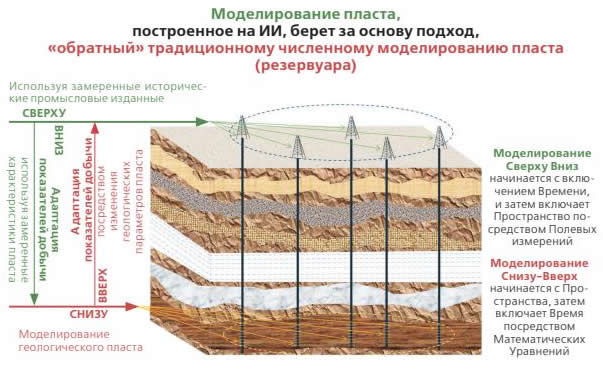
В искусственном интеллекте данные не служат нашему пониманию физического явления, а используются для создания модели физического явления без использования каких-либо математических уравнений. Когда искусственный интеллект моделирует физические явления на основе реальных измеренных данных, то он не будет делать никаких предположений, интерпретаций и упрощений. Симуляция и моделирование резервуаров на основе ИИ («Сверху вниз» Top-Down) полностью отличается от того, что многие крупные сервисные компании, и почти все поставщики, предлагают, утверждая, что они могут построить моделирование резервуаров на основе ИИ. Моделирование методом Top-Down следуют реалистичному инженерному применению искусственного интеллекта, не использует поскважинный Анализ кривой падения с использованием машинного обучения, и не использует большой объем данных, сгенерированных математическими уравнениями (как в Гибридных моделях).
– Говоря в целом, д-р Мохагех, не могли бы вы привести несколько ярких примеров того, как ИИ потенциально может, или уже изменил «то, что мы всегда делали в нефтяной инженерии?
– Да, конечно. Хорошими примерами являются «Моделирование и моделирование резервуаров на основе ИИ (сверху вниз)» (Моделирование сверху вниз – TDM) и Моделирование интеллектуальных прокси. В книге SPE, которую я написал в 2017 году (Моделирование резервуаров на основе данных), объясняются основы нисходящего моделирования. С 2017 года по настоящее время (2022 год) TDM значительно улучшился. Недавно я написал новую книгу под названием «Smart Proxy Modeling. Вот ссылки и фото книг.
-
Title: Smart Proxy Modeling – Artificial Intelligence and Machine Learning in Numerical Simulation (ISBN: 978-1-032-15114-4) 2022, Publisher: CRC Press Taylor & Francis Group. LLC
-
Title: Data Driven Reservoir Modeling (ISBN: 978-1-61399-560-0) 2017, Publisher: Society of Petroleum Engineers (SPE)
Вот краткое объяснение «Моделирования смарт-прокси» и «Моделирования сверху вниз»:
Компания Intelligent Solutions.Inc разработала два различных приложения искусственного интеллекта для моделирования и моделирования резервуаров. Первое приложение называется «Моделирование смарт-прокси», а второе приложение называется «Моделирование сверху вниз».
Интеллектуальное прокси-моделирование: В этой технологии искусственный интеллект предоставляет прокси-модель численного моделирования резервуара, которая сильно отличается от традиционных прокси-моделей, которые использовались в последние несколько десятилетий. Smart Proxy Modeling не упрощает и не изменяет основное математическое уравнение, которое использовалось для построения численного моделирования коллектора, и не уменьшает количество ячеек, которые изначально использовались при численном моделировании коллектора.
Интеллектуальное прокси-моделирование не использует традиционную статистику для создания только определенной части численного моделирования. Интеллектуальное прокси-моделирование обеспечивает точность более 95% результатов численного моделирования коллектора для всех ячеек всего за несколько минут на ноутбуке. Для разработки интеллектуального прокси-моделирования требуется всего от 20 до 30 прогонов численного моделирования коллектора Моделирование сверху вниз (нисходящее): в этой технологии искусственный интеллект обеспечивает моделирование коллектора, которое сильно отличается от традиционного численного моделирования коллектора. Моделирование коллектора на основе ИИ (сверху вниз) не использует математические уравнения и для моделирования использует только фактические полевые измерения, а также избегает любых предположений, интерпретаций и упрощений.
Численное моделирование коллектора, которое использовалось в нефтяной промышленности в прошлом веке, представляет собой моделирование коллектора “снизу вверх” (восходящее). Оригинальная геологическая модель пласта (низ) разрабатывается геологами и используется инженерами-коллекторами для подгонки модели по данным добычи (верх). Моделирование коллектора на основе ИИ – это моделирование коллектора “сверху вниз”.
Историческая добыча, включающая подробную информацию о каждой скважине на месторождении и всех эксплуатационных условиях, связанных с поверхностью (верху), используется для геоаналитики (ИИ геологического моделирования) для моделирования геологии пласта (низ) для прогнозирования добычи и оптимизации добычи.
В отличие от многих других подходов, которые в настоящее время используются нефтесервисными компаниями и компаниями-поставщиками (Искусственный общий интеллект), моделирование коллектора на основе ИИ (сверху вниз) представляет собой модель всего месторождения, а не модель, основанную на одной скважине, она следует этике ИИ и избегает использования “гибридных моделей”, которые включают данные, генерируемые с помощью математических уравнений. Нисходящее моделирование включает в себя научное и инженерное применение искусственного интеллекта.
– В TDRM, где модель строится «обратно» традиционному подходу, геологическая часть не является «исходной и основной» точкой. Каково значение (или необходимость) геологической модели в моделировании TDRM в данном случае?
– Симуляция резервуаров (месторождений) и Моделирование (Сверху вниз, Top-Down) на основе искусственного интеллекта практически объединяет пласт, ствол скважины и наземные объекты для моделирования потока жидкости в пористой среде. TDRM разрабатывает геоаналитику, которая представляет собой геологическую модель, построенную на основе искусственного интеллекта. TDRM делает это, используя данные «сверху», которые включают в себя все дебиты, характеристики всех стволов скважин на месторождении и все условия эксплуатации на поверхности (настройка штуцера, устьевое давление, давление в выкидной линии и т. д.). для построения модели резервуара для оптимизации добычи за счет оптимизации операционных и капитальных затрат.
– «Все модели ошибочны, но некоторые из них полезны», сказал Джордж Э.П. Бокс.
Как правило, геологические и резервуарные (динамические) модели строятся на основе предвзятых знаний их «создателей» – коллектива или отдельных лиц. Очень часто, как только модель по какой-либо причине меняет «хозяев» - та же самая модель, с теми же входными данными будет «скорректирована» или даже перестроена новой командой, чтобы отразить «новое» понимание модели резервуара. Можем ли мы ожидать, что модели, построенные с использованием ИИ/МО, будут нечувствительны к «человеческому предубеждению»?
– Это замечательный вопрос, который очень верен с точки зрения инженерной экспертизы. В этом заключается основное различие между моделированием коллектора на основе ИИ (Сверху вниз, Top-Down) и традиционным численным моделированием коллектора, поскольку TDM основан только на фактических измеренных данных и позволяет избежать любых предположений, интерпретаций и упрощений. Модель TDM построена только на фактах и реальности, а не из того, что мы думаем и во что верим. Единственный момент, который необходимо упомянуть, заключается в том, что разработка TDM требует большого опыта в области искусственного интеллекта и проектирования резервуаров.
– Эмпирические методики в виде математических соотношений являются отраслевым стандартом для представления подземных процессов, происходящих при добыче углеводородов. В вашем многолетнем опыте сталкивались ли вы со случаями, когда некоторые из этих стандартных методов «не работали» или оказывались устаревшими, а вместо этого альтернативные, новые и надежные процедуры, сгенерированные ИИ/МО, были теми, которые «лучше всего подходят» для старой проблемы. Существуют ли какие-либо конкретные примеры используемых в настоящее время методологий, которые можно легко заменить?
– Несколько первоначальных проектов, которые мы получили от многих компаний (в основном на Ближнем Востоке и в Юго-Восточной Азии) на использование принципов TDM (Top-Down Modeling) на основе ИИ для моделирования резервуаров, дали точно такие результаты, как вы сформулировали в вашем вопросе «случаи, когда некоторые из этих стандартных методов не работали». Как только мы применили TDM вместо традиционного численного моделирования резервуара, было продемонстрировано, что искусственный интеллект может предоставить гораздо более качественные и основанные на фактах модели для оптимизации добычи нефти и определения локаций для бурения следующих уплотняющих скважин c целью увеличения добычи нефти. В таких проектах TDM смог обеспечить высокоточное сопоставление истории (history match) добычи нефти, газа и воды, в то время как таких результатов невозможно было достичь с помощью численного моделирования коллектора, и это было основной причиной по которой они связались с нами, c запросом на использование TDRM.
Пример нахождения оптимальной для уплотняющих скважин локации, предоставленной TDM, в сравнении с локацией, найденной с применением численного моделирования коллектора, был представлен на панельной сессии менеджером компании в 2020 ATCE (Annual Technical Conference and Exhibition).
– Не могли бы вы подробнее остановиться на анализе нефтяных данных?
– Аналитика нефтяных данных (АНД) включает в себя научное и инженерное применение искусственного интеллекта в нефтяной инженерии. Целью АНД является решение проблем нефтяной инженерии и принятие решений. АНД будет полностью контролировать будущее науки и техники в нефтяной промышленности. Для нового поколения ученых и специалистов в области нефтяной промышленности очень важно выработать правильное и реалистичное понимание искусственного интеллекта.
Как и применение этой технологии в других инженерных направлениях, анализ нефтяных данных решает две основные проблемы, которые определяют успех или неудачу этой технологии в нашей отрасли: (а) различия между “инженерным” и “не инженерным” решением проблем и принятием решений, и (б) как ИИ отличается от традиционного решения инженерных задач и традиционного статистического анализа.
В последние несколько лет отсутствие успеха или посредственные результаты ИИ в нашей отрасли были довольно распространенным явлением. В значительной степени это связано с поверхностным пониманием ИИ компаниями и поставщиками нефтегазовых инженерных услуг и их концентрацией на маркетинговых схемах, а не на науке и технике.
– Помимо управленческих решений и технических возможностей, что, по вашему мнению, необходимо для того, чтобы искусственный интеллект стал технологией статус-кво в нефтяной промышленности?
– Искусственный интеллект – это часть новой научной революции, которая через несколько десятилетий изменит все в нашем мире. Когда дело доходит до инжиниринга и, в частности, “нефтяного инжиниринга”, будущее нашей отрасли во многом зависит от искусственного интеллекта. Это технология, которая улучшит все в нашей отрасли по сравнению с прошлым веком. С помощью ИИ все в нашей отрасли становится более реалистичным и намного быстрее. То же самое произойдет и со всеми другими отраслями промышленности. Вспомните “Промышленную революцию” 18-го века. Революция искусственного интеллекта будет гораздо важнее и намного быстрее.
– В упрощенной форме мы можем сказать, что ИИ/МО специалисту необходимо ввести входные данные и определить требуемый результат. Затем путь между этими двумя точками “строится” самими встроенными алгоритмами машинного обучения. Какой потенциал могут иметь концепции, называемые “Бескодовые” и “Малокодовые” (акцент на использовании графического интерфейса, а не на “жестком кодировании”), которые могут быть интегрированы в практику инженеров ИИ/МО? Чтобы он/она могли сосредоточиться на основной работе, а не думать о том, как правильно его закодировать?
– Важно отметить определение "Машинного обучения", чтобы ответить на этот вопрос: “Машинное обучение” – это наука о том, как заставить компьютеры действовать (а) без явного программирования и (б) с помощью Открытых Компьютерных Алгоритмов и обучения на основе данных.
Когда кому-то нужно использовать алгоритмы машинного обучения для решения проблем, это не означает, что нужно знать, как кодировать алгоритм.
Причиной этого является большое количество программных кодов, которые уже были разработаны и предоставлены всем бесплатно. Однако инженерам и ученым важно знать и понимать математические детали всех алгоритмов машинного обучения, которые они используют для создания моделей на основе искусственного интеллекта. Причина этого заключается в том, что знание математических деталей всех алгоритмов машинного обучения поможет им использовать закодированный алгоритм гораздо эффективнее. В то же время ученые и инженеры должны понимать, что подход ИИ сильно отличается от традиционного моделирования физических явлений с помощью математических уравнений. Поэтому они должны понимать, что знание математических деталей всех алгоритмов машинного обучения не означает, что они становятся экспертами в области искусственного интеллекта.

Для решения проблем, связанных с наукой и инженерией, с использованием ИИ с помощью Алгоритмов машинного обучения, в отличие от традиционной чтобы использовать все полученные данные, а затем использовать их в качестве входных данных для алгоритма машинного обучения для моделирования выходных данных, которые являются вашей целью. Правильное использование доступных “реальных” и “фактических” данных (в нефтяной инженерии это данные полевых измерений) заключается в использовании ваших знаний в области нефтяной инженерии для “обучения” алгоритма машинного обучения выходным данным. Этот процесс за последние два десятилетия доказал мне, что более 50-60% времени в моделировании на основе искусственного интеллекта в науке и технике потребуется на работу с данными, полученными для «обучения» алгоритмам машинного обучения.
– ИИ с технической точки зрения – очень мощная технология. Тем не менее, довольно необычно для технического термина, но слово “Этика” появляется в сочетании с ИИ. Не могли бы вы, пожалуйста, подробнее рассказать о значении этики ИИ? И ее специфики в нефтяной промышленности.
– Всё верно. К сожалению, некоторые ученые и инженеры считают, что этика искусственного интеллекта неприменима к использованию научных и инженерных задач с использованием ИИ. Чтобы ознакомиться со всеми деталями этики ИИ и с тем, как она применима к решению научных и инженерных задач с использованием ИИ, пожалуйста, обратитесь к следующим двум статьям, которые я написал на эту тему:
ИИ-этика в инженерном деле; Предвзятость традиционных инженеров в моделировании физики на основе ИИ (Части 1 - 2)
Шахаб Мохагех – 6 сентября 2021 года - Medium.Com
https://shahab-mohaghegh.medium.com/ai-ethics-in-engineering-65ab23af3f76
https://shahab-mohaghegh.medium.com/ai-ethics-in-engineering-437ec07046a6
– «Программное обеспечение пожирает мир, но ИИ съест программное обеспечение» (Дженсен Хуанг). Какой вы видите взаимосвязь между так называемыми «отраслевыми стандартами» программного обеспечения и новыми продуктами, созданными на основе искусственного интеллекта/машинного обучения? Будет ли синергия или конкуренция?
– В настоящее время существует несколько программных приложений на основе ИИ (машинного обучения), которые могут быть использованы в нефтяной промышленности для разработки на основе ИИ (сверху вниз) моделирования коллекторов и Сланцевой аналитики. Вот программные приложения и ссылка, чтобы узнать о них больше:
1) IMagine – Software Application for “AI-based (Top-Down) Reservoir Simulation and Modeling” - http://www.intelligentsolutionsinc.com/Products/IMagine.shtml
2) IMprove – Software Application foe “Shale Analytics” – http://www.intelligentsolutionsinc.com/Products/IMprove.shtml
– Есть хорошая поговорка: “Программное обеспечение настолько хорошо, насколько хороши люди им пользующиеся”. Ссылаясь на эту аналогию, каковы требования к специалистам по ИИ, чтобы стать “хорошими” в использовании технологий искусственного интеллекта/машинного обучения?
– Это абсолютно верно. Используя программное обеспечение ИИ, специально предназначенное для науки и техники, пользователь должен ознакомиться с реальностью того, как ИИ используется для решения проблем, связанных с наукой и инженерией. Это требует очень большого опыта и исследований.
Нужно задаться вопросом “сколько времени и какой объем работы необходим, чтобы стать экспертом-инженером-нефтяником?”. Для того, чтобы стать экспертом в области искусственного интеллекта потребуется столько же опыта и упорного труда.
– Что вы могли бы посоветовать начинающим специалистам по искусственному интеллекту, чтобы добиться успеха в своих начинаниях?
– Изучите следующие направления очень подробно:
-
История искусственного интеллекта
-
Правильные определения искусственного интеллекта
-
Научное и инженерное применение искусственного интеллекта
-
Моделирование физики с использованием искусственного интеллекта
-
Искусственный интеллект в сравнении с традиционной статистикой
-
Этика искусственного интеллекта (AI-Ethics)
-
Объяснимый искусственный интеллект (XAI)
Обычно я преподаю короткие курсы по этим темам.
– Спасибо вам за исчерпывающие ответы!
Арман Мухамедьяров, инженер по разработке
info@petroleumchronicle.com